
Najważniejsze
|
Newsy
|
Recenzje
6 lipca 2026

Równolegle do dużych modeli językowych LLM, które stoją za tekstowymi asystentami AI bardzo szybko rozwija się inna gałąź sztucznej inteligencji – generowanie obrazów jedynie na podstawie promptów, czyli naszych opisów słowami. Możliwe zastosowania są bardzo szerokie - od poszukiwania inspiracji, przez wizualizację pomysłów, stworzenie logo, a na ilustracjach do tekstów kończąc.
Obecnie wiodące modele AI do generowania obrazów to:
Midjourney to model stworzony przez niezależną firmę, która skupia się tylko na generowaniu grafiki przez AI i jest dostępny jako otwarta beta. Midjourney jako jedyny model nie oferuje obecnie darmowego okresu próbnego i wymaga wykupienia subskrypcji, która zaczyna się od 52 zł miesięcznie. Z Midjourney można korzystać tylko za pomocą platformy do komunikacji Discord, w której trzeba założyć osobne konto. Polecenia wpisujemy korzystając z funkcji dostępnego na Discord Bota. Liczba możliwych parametrów generowania obrazu jest ogromna, ale w związku z tym Midjourney jest najmniej intuicyjny w użyciu, choć daje największe możliwości.
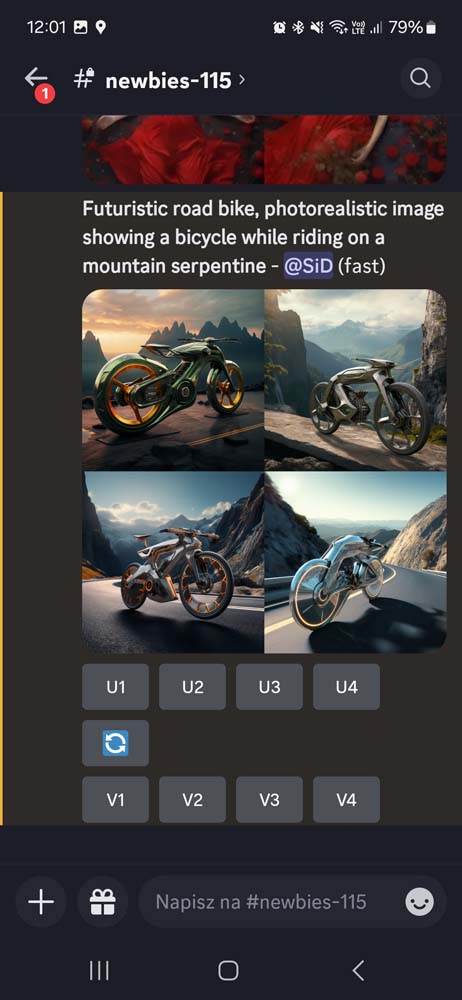
Wszystkie wygenerowane grafiki pojawiają się na publicznym czacie, gdzie swoje obrazy generują inni użytkownicy. Midjourney każdorazowo generuje 4 wersje obrazu, o który prosimy. Galerię stworzonych przez nas obrazów możemy obejrzeć pod tym adresem, na stronie Midjourney.
Z Discord można korzystać zarówno przez przeglądarkę jak i za pomocą dedykowanej aplikacji.
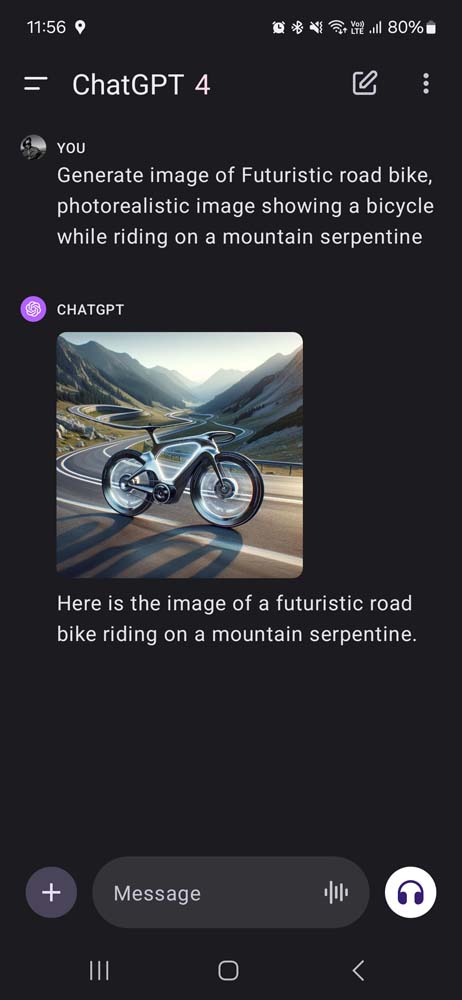
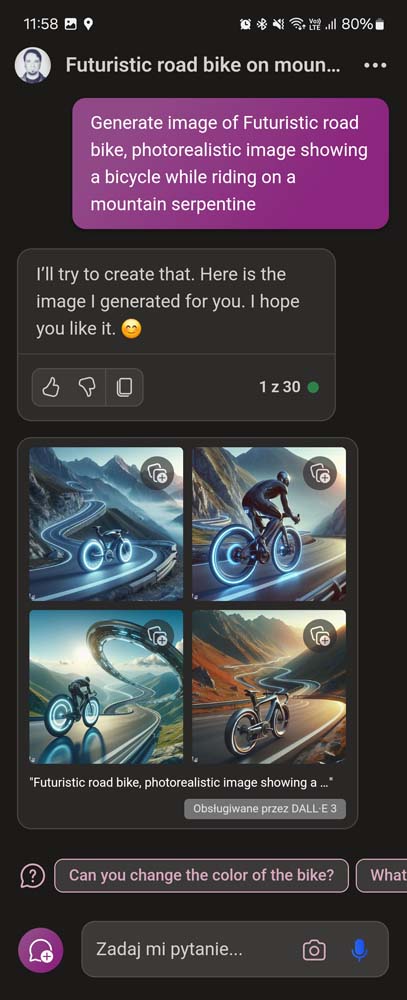
DALL-E 3 został opracowany przez OpenAI, firmę, którą stworzyła ChatGPT, najbardziej popularny produkt AI na rynku. DALL-E 3 jest zintegrowany z ChatGPT pod warunkiem, że korzystamy z płatnego planu subskrypcji ChatGPT Plus. Możemy w ten sam sposób co rozmowa z ChatGPT poprosić o wygenerowanie obrazu i dowolnie go opisać. DALL-E 3 nie ma tylu parametrów co Midjourney, ale jest zdecydowanie bardziej intuicyjny w użyciu. Można z niego korzystać zarówno w aplikacji mobilnej jak i w przeglądarce. Domyślnie tworzy pojedynczą wersję obrazu.
Jest też możliwość skorzystania z DALL-E 3 za darmo, podobnie jak z ChatGPT 4.0 – za pomocą aplikacji Copilot od Microsoft. Sposób tworzenia obrazów nie różni się od tej w ChatGPT, ale domyślnie dostajemy propozycje 4 obrazów, jak w Midjourney. Microsoft daje użytkownikom tokeny – ulepszenia, które pozwalają generować grafikę bez opóźnienia. Gdy je wyczerpiemy darmowe tworzenie grafiki może potrwać dłużej. Generowanie grafiki jest dostępne w aplikacji mobilnej Copilot.
Meta, jak sama nazwa wskazuje, należy do firmy odpowiedzialnej za powstanie Facebooka. Jest obecnie uważana za najlepszy darmowy generator obrazów, ale niestety nie jest dostępna w Polsce.
Firefly to produkt należący do Adobe – producenta oprogramowania, w tym powszechnie znanego Photoshopa. Osoby mające konto Adobe mogą korzystać z Firefly za darmo. Z przetestowanych rozwiązań to działa najszybciej. Adobe rozwija generowanie grafiki AI przede wszystkim pod kątem integracji z Photoshopem, który pozwala wykorzystać generowanie obrazu podczas edycji, aby np. wypełnić pustą przestrzeń. Jako samodzielny produkt jest raczej polem doświadczalnym pozwalającym rozwijać technologię.
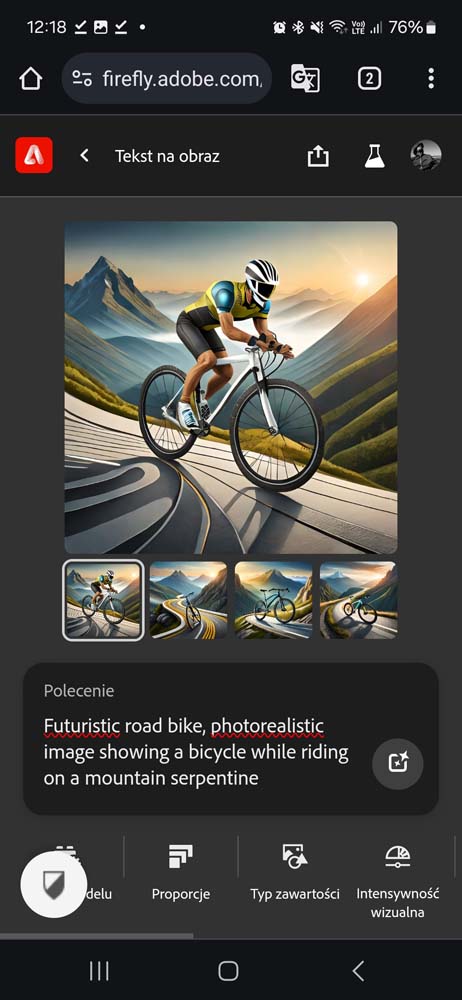
W Firefly obok pola tekstowego w którym umieszczamy opis (prompt) można wybrać dodatkowe parametry: proporcje, typ zawartości – zdjęcie lub sztuka, a także ustawić intensywność wizualną za pomocą suwaka.
Stable Diffusion to model, który powstał przy współpracy Uniwersytetu Ludwika i Maksymiliana w Monachium z firmą Runway AI. Jako jedyny został udostępniony na otwartej licencji i każdy może go pobrać, uruchomić na prywatnym komputerze, a nawet modyfikować. Wymaga to jednak odpowiedniej znajomości zagadnień technicznych, a przypadku modyfikacji także programowania. Można też skorzystać z Stable Diffusion za pomocą serwisów online, które ułatwiają dostęp do tej technologii przez przeglądarkę lub aplikację mobilną. Wówczas udostępniają one tylko moc obliczeniową serwerów, a nie całą technologię, jak ma to miejsce w przypadku innych modeli generujących grafikę.
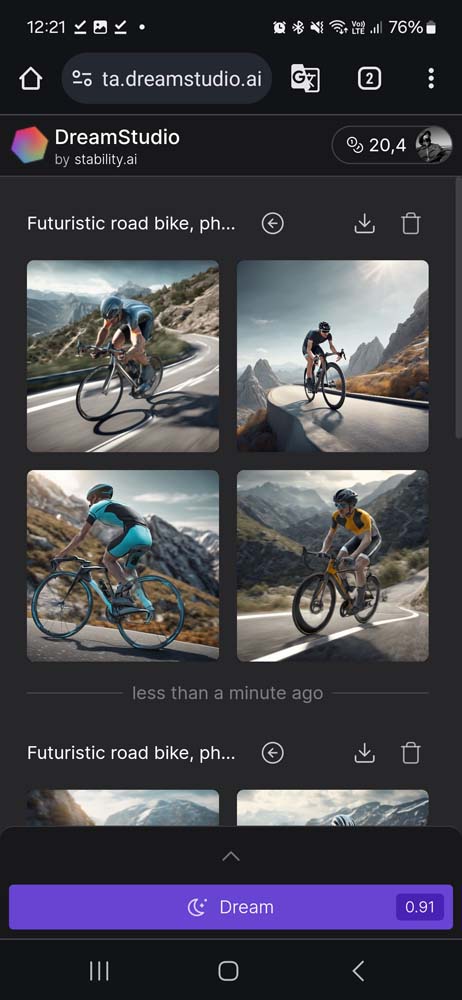
Serwis Dreamstudio, który pozwala korzystać z modelu Stable Diffusion ma kilka dodatkowych opcji poza miejscem na wpisanie opisu. Jest osobne pole do opisu czego dany obraz ma nie zawierać. Można ustawić proporcje i liczbę generowanych obrazów od 1 do 10 sztuk. Można też wgrać inny obraz, aby powstały jego wariacje. Możliwe jest również wybranie jednego ze stylów grafiki na wzór filtrów w Instagram czy aplikacji aparatu.
Praktyka pokazała, że są elementy obrazów, które dla sztucznej inteligencji są trudniejsze do wykonania. Dużą barierą, która częściowo już została pokonana jest generowanie tekstu na obrazie oraz ludzkich dłoni.
Podczas testów wzięliśmy te problemy celowo pod uwagę i sprawdziliśmy które modele AI do generowania obrazów potrafią sobie z nimi poradzić.
Przygotowałem kilka opisów grafik do wygenerowania. Opisy były przetłumaczone na język angielski, aby uniknąć ewentualnych różnic wynikających ze stopnia rozumienia języka polskiego. Ograniczyłem szczegółowość opisów i liczbę parametrów, aby wyrównać szanse wszystkich modeli. To porównanie jest skierowane bardziej do osób początkujących, które nie mają jeszcze doświadczenia w przygotowywaniu zaawansowanych promptów. Ograniczyłem się do wymuszenia najnowszego silnika Midjourney v6 oraz stylów konkretnych artystów.
W przypadku futurystycznego roweru szosowego jadącego górską serpentyną DALL-E 3 w wersji ChatGPT oraz Copilota postawił na dość klasyczny kształt ramy, dodając neonowe koła. Połowa grafik to był sam rower, połowa z rowerzystą. Midjourney poszedł w bardziej futurystyczne kształty, ale przypominające bardziej motocykl elektryczny niż rower. Firefly mimo opisu stawiającego wymóg fotorealizmu stworzył ilustrację z klasycznym rowem z prostą kierownicą. Stable Diffusion najwierniej odwzorował nowoczesne rowery szosowe jakie znamy i na każdym umieścił rowerzystę. Może nie były bardzo futurystyczne, ale wyglądały przekonująco jako rowery.

Kolejne polecenie dotyczyło futurystycznego, składanego smartfonu w stylu Zdzisława Beksińskiego. DALL-E 3 najwierniej odwzorował mroczny styl, ale można mieć wątpliwości czy to tył smartfonu czy być może okładka księgi. Copilot korzystający z tego samego modelu w ogóle nie oddał mrocznej atmosfery, ale wiernie odtworzył składane smartfony. Midjourney osiągną najlepszy kompromis pomiędzy nowoczesnością, przyszłą formą smartfonu i stylem. Za to Firefly poległ kompletnie, pokazując zdarzenie czegoś co przypomina pierwszego iPhone’a z radosnym, kolorowym tłem. Stable Diffusion stworzył rozmaite elastyczne ekrany na jednolitym tle.

Wszystkie modele wywiązały się dobrze z polecenia stworzenia szkicu futurystycznych głośników w stylu ilustracji Alexa Pardee.

Midjourney ma niekwestionowaną przewagę w jakości tworzenia fotorealistycznych portretów. Firefly jako jedyny nie wywiązał się z realizacją zlecenia – wygenerował starszą panią, ale bez tatuażu i bez krótkich włosów, jak było w poleceniu.

Projektowanie futurystycznej zabawki to kolejne zdanie, które Midjourney wykonał wzorowo, a Firefly stworzył małe porcelanowe figurki, które trudno nawet uznać za zabawki w tradycyjnym rozumieniu.

Polecenie stworzenie dwóch dłoni – jednej trzymającej smartfon i drugiej pokazującej pięć placów – od razu wykazało, że jest to zadanie, do którego zdolny jest tylko Midjourney. DALL-E 3 czasami nadawał dziwny wygląd skórze, czasami dodawał palce. Firefly i Stable Diffusion stworzyły istne abominacje.

Przy poleceniu stworzenia witryny sklepowej z napisem informującym o wyprzedaży o dziwo najlepiej sprawdził się DALL-E 3, który nie popełnił błędu w napisach, jak i witryny sklepowe okazały się przekonująco prawdziwe. Midjourney mniej więcej radził sobie z napisami, ale ani razu nie zacytował go w całości. Pozostałe modele miały jeszcze większe problemy.

Pod względem wszechstronnych możliwości bezkonkurencyjny jest Midjourney. Najlepiej sprawdza się w fotorealistycznych obrazach, portretach, potrafi stworzyć anatomicznie poprawne ludzkie dłonie. Z napisami nie jest idealnie, ale można coś próbować osiągnąć metodą kolejnych prób.
Jest to jednak model, który tym więcej daje od siebie im bardziej szczegółowy opis mu podamy. Jeśli nie będziemy korzystać z zaawansowanych parametrów ominie nas większość możliwości tego modelu. To też jedyna propozycja z tego zestawienia, która nie ma obecnie darmowej wersji. Mimo wykupienia abonamentu musimy generować obrazy na publicznym kanale Discord i założyć dwa osobne konta, dla komunikatora i dla Midjourney. Można powiedzieć, że dla efektów warto to zrobić, ale nie da się ukryć, że całe doświadczenie jest najmniej zoptymalizowane pod kątem zwykłego użytkownika.
DALL-E 3 jest drugi pod kątem możliwości i jednocześnie najlepiej radzi sobie z interpretacją opisu. Jest wygodny w obsłudze, bo można z niego korzystać w ten sam sposób co z asystenta AI – po prostu opisując co chcemy zobaczyć. W naszym teście najlepiej poradził sobie z napisami, ale z dłońmi ma duże problemy.
Wyjątkowość Stable Diffusion polega na tym, że to jedyny model, który możemy uruchomić na własnym komputerze. Zależnie od tematyki obrazów albo jest na trzeciej pozycji za DALL-E 3, albo sporadycznie awansuje na drugie miejsce. Dostępne w sieci usługi pozwalają wybrać dodatkowe parametry za pomocą wygodnego interfejsu, bez znajomości poleceń.
Adobe Firefly najgorzej poradził sobie z interpretacją poleceń. Jako jedyny model kilkukrotnie stworzył coś zupełnie niespełniającego warunków jakie otrzymał. Potrafi tworzyć fotorealistyczne obrazy, o ile przypominają one sceny, które moglibyśmy spotkać w prawdziwym życiu. Nie ma jednak „wyobraźni” aby zaprojektować coś jeszcze nieistniejącego jedynie na podstawie opisu.
Należy pamiętać, że nasz test to jedynie migawka obecnych możliwości. W ciągu kilku miesięcy krajobraz generatorów obrazów może się diametralnie zmienić. Moim zdaniem Midjourney najbardziej brakuje pełnoprawnego interfejsu, który nie wymagałby korzystania z bota na Discordzie. Gdy będzie można z niego korzystać za pomocą suwaków i przełączników wprost w oknie przeglądarki, całkowicie zdeklasuje konkurencję.








